How To Measure Your House
How do you measure your house to get the square footage of vinyl siding you will need?
Question Number One
Where To Start
How big is your house?
 Do you live in a small one story house?
Do you live in a small one story house? Do you live in a two + story house?
Do you live in a two + story house?Knowing how much vinyl siding you will need to cover your house is the first question in determining your overall budget. And the first thing you will need to know when you call the home improvement store to get prices.
Before you go shopping for vinyl siding, you first want to know approximately how much siding you will need.
Vinyl siding is sold by the square foot. Actually it is sold in 100 sq ft boxes.
So you must calculate the total square footage of the exterior walls on your house.
This sounds daunting, but it is really quite easy. In fact you can have fun doing it.


Items You Will Need to Measure Your House
You only need several items to measure your house.
- A tape measure
- A note book or several sheets of paper stapled together
- A sunny afternoon
- A wife and kids that are willing to help.
Measuring your house can be turned into a family affair.
Get the wife and kids and go outside and measure the exterior walls on your house.
How To Figure Out How Much Vinyl Siding To Buy
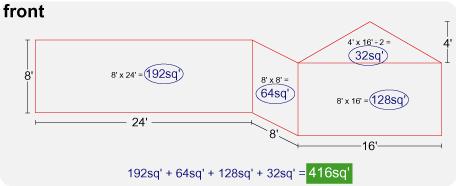
Height (8') X Width (40') = Sq ft (8' x 40' = 320 sq ft)

1/2 Height X width = sq ft of gable
Part 1. Length
Draw your house on one of the pages of the notebook. Just the walls, like you are looking down from above the house. Don't worry about the roof, just draw the exterior walls.
Walk outside and face your front door. Start at the front door and walk clockwise (left to right) to the first corner of your house. That corner is Corner #1. Write corner #1 on your house sketch.
Then measure from that corner to the next corner all the way around the house until you get back to corner #1.
Measure and write down the numbers for each wall, from corner to corner on your house sketch.
You are going to be measuring from corner to corner, in feet. If the measurement is say 30' and 6", always go to the next whole number. So that measurement would be 31'.
If you have a house with only four corners, it won't take you long to measure. It your house has 10 corners, well, it will take longer.
Have the wife and kids help you write down the numbers.
Let the kids hold the measuring tape ends. Make it fun and involve the whole family.
You should now have the total number of feet, from corner to corner, all around your house.
Write this number down on your house sketch.
Label this number the Total Length of House.
What About the Windows and Doors?
NOTE:
I know that windows and doors are not covered with vinyl siding. Some people tell you to measure all your windows and door and subtract that number from the total sq footage from the walls.
Way to much trouble. Unless you have a ton of windows and doors, don't worry about them. You are just trying to get an approximate number of square feet and the windows and door will not make that much difference anyway.
Part 2. Height
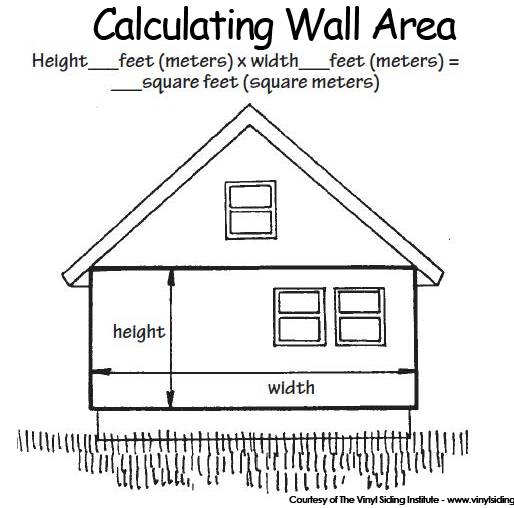
Since we are finding the total square footage of your exterior walls, there is the formula to determine it. L X H = Sq Ft
That formula is Length x Height = Square Footage
(the total length of all the walls x the height from the ground to the soffit)
The second part of the measurement we need to determine will be the height from the ground to the soffit or facia board (what the gutters are nailed to).
Wall are generally 8' or 9'. And it will be the same all around your house.
Take your tape measure and measure from the ground to the overhang.
Remember that the height of your exterior walls will be the same, from the ground to the soffet or gutters. Length x width = square feet. (the total length of all the walls x the height from the ground to the soffit)
EXAMPLE:
Say your house is 40' x 60'. You will have a 40'+40'+60+60 wall. Add them up, you get 200' of exterior walls. (40+60+40+60=200)
If the height of your walls are 8'. Now you have your formula.
200' x 8' = 1,600 sq ft.
Your house has approximately 1,600 sq ft of exterior walls.
Vinyl siding is sold by the square foot.
Once you know that you have 1,600 sq ft of exterior walls, you can call several of the local big box stores like Home Depot and Lowes, and ask them what the going rate that contractors are charging to hang vinyl siding.
They will tell you that the going rate is around $5 to $7 per square foot, depending upon the grade of vinyl siding. (These are totally made up numbers, each geographic area will be different)
This dollar figure should include the siding, insulating board and labor to install the vinyl siding only.
It does not include add-on's and extras, nor the building prep to install the vinyl siding on your house. And certainly no repair work on your house.
What If I Have a Two Story House?
If you have a two-story house you will measure the same way, from corner to corner. You may have to estimate the exact length by looking up at the second floor while standing on the ground.
You should be able to get pretty close. Remember, vinyl siding is sold in boxes of 100 sq ft. So approximate number are just fine. Also, you always want to have an extra box of the siding in case there is damage to the vinyl siding sometime from heat, wind or other thing.
You will probably not be able to ever get the exact same color again.
What If I Have a Gable End How Do I Measure It?
Ok this is easy too! Measure how wide the gable is, corner to corner, or edge to edge.
Say the gable is over the garage and the garage is 28' wide. The length of the bottom part of the gable will be 28'. This number is called the base.
Now the distance from the top of the exterior wall, (your wall will be 8' or 9') to the top of the roof, or the point of the roof, say is 6'
Top of the wall to top of the roof, 6 feet.
You have a big triangle that is 28' by 6'. That is the gable.
Formula for find the area of a triangle, base x height divided by 2.
28' x 6' = 168 sq ft divided by 2 = 84 sq ft.
Your gable has approximately 84 sq ft. Just add that number in to the other numbers to get the total square footage.
Click here to go back to Vinyl Siding Costs
Click here to go back to Vinyl Siding Home Page
Looking for Trusted Local Siding Pros?
Find and contact top-rated local siding contractors in your area. Get a quote, ask questions about siding prices, styles, types, or just get more information. Get started below!



Welcome To: All-About-Siding.com Contractors sharing their tips and knowledge with homeowners. Compare types, styles, prices, colors and more. We would love to hear from you with suggestions, tips, pictures, and stories about your experience in choosing a siding for your house.